
Thoughts on Feature Selection
All practioners of ML know that feature selection is important and is helpful to reduce the unwanted signal in your dataset.
Feature selection methods can be categorised as follows:
- Filter methods e.g selection based on co-relation, mutual information.
- Wrapper methods e.g recursive feature elimination.
- Embedded methods e.g Tree based feature importances.
All methods suffer from some advantages and disadvantages.The primary distinguishing factors being speed vs chances of overfitting. In terms of speed Filter methods are faster than embedded methods which are faster than wrapper methods. Wrapper methods have a higher chance of overfitting compared to embedded and filter methods.
To balance out the pros and cons a combined approach can be followed as shown below:
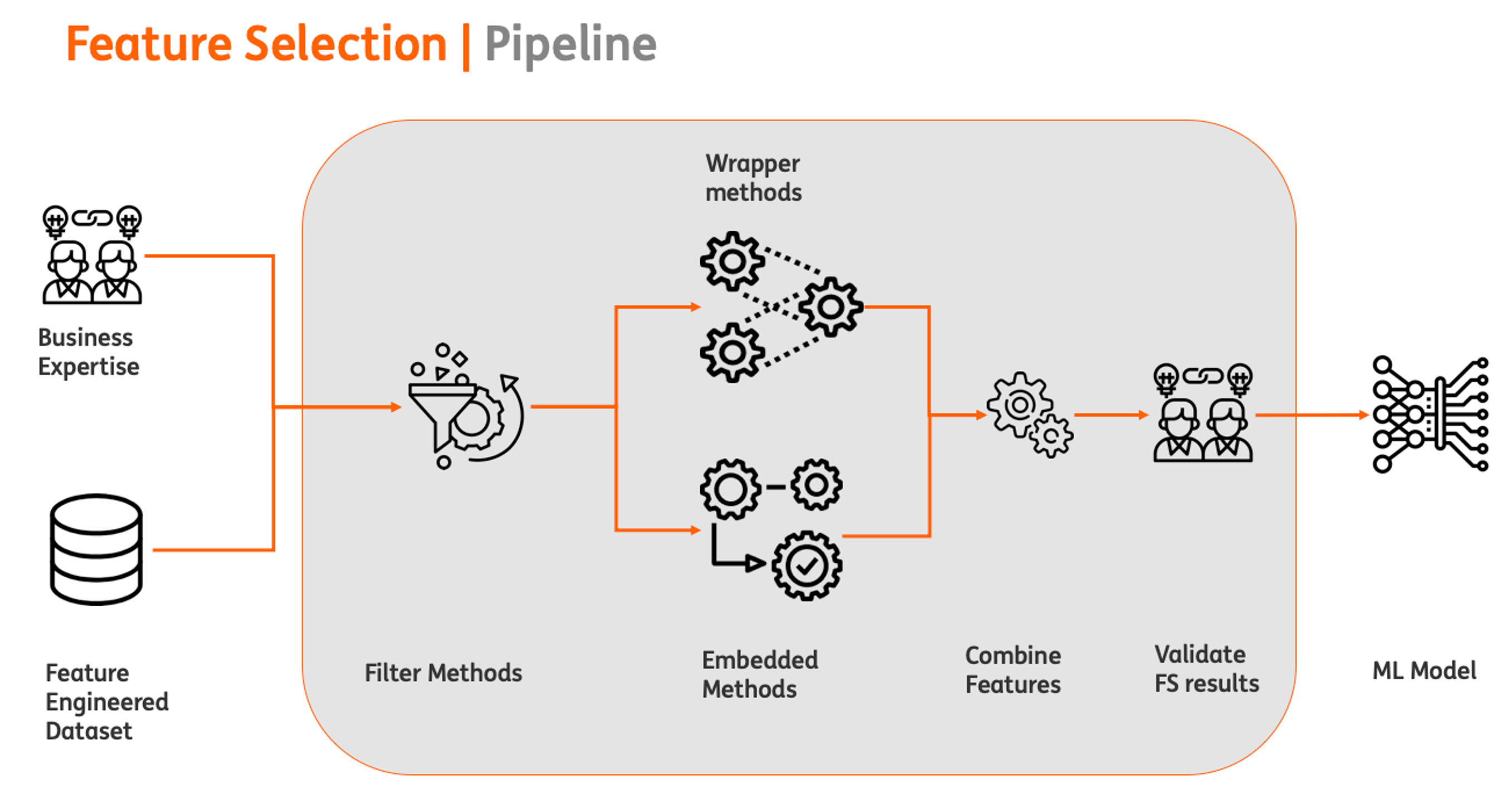
The main points to take into consideration are :
-
Feature selection should be done in consultation with the business experts.They have insights into the business problem and can guide in eliminating some features right away e.g some feature which are very unstable or in the case of co-related feature which features to eliminate etc. They can also validate the results of feature selection.
-
Bootstrapped sampling strategy can be used for feature selection, as features which are important in the entire dataset will be important in the sampled data as well.